
关键词:population structure,cryptic relatedness,spurious association,LMM,GRM
早期的GWAS研究使用的模型为固定效应的线性模型,但通常会受两方面混淆因素的影响:
- 群体结构/分层 (population structure/ stratification):研究群体中存在有不同祖先(ancestry)的亚群体(subgroup)
- 隐性关联(cryptic relatedness):研究样本之间存在未知的亲缘关系
如果在模型中故意忽略掉这些混淆变量(confounding variable),就很可能导致结果出现假阳性(false positive)或是虚假关联(spurious association),所以这是我们在进行GWAS研究时,必须要考虑的问题。
Population structure
首先来看群体结构/分层
考虑一个case-control研究,如下图所示,红色的群体在整体样本中占了case的大多数,那么一些对疾病并没有影响,但在红蓝两群体之间等位基因频率相差很大的genetic marker,就有可能会造成虚假关联(spurious association)。
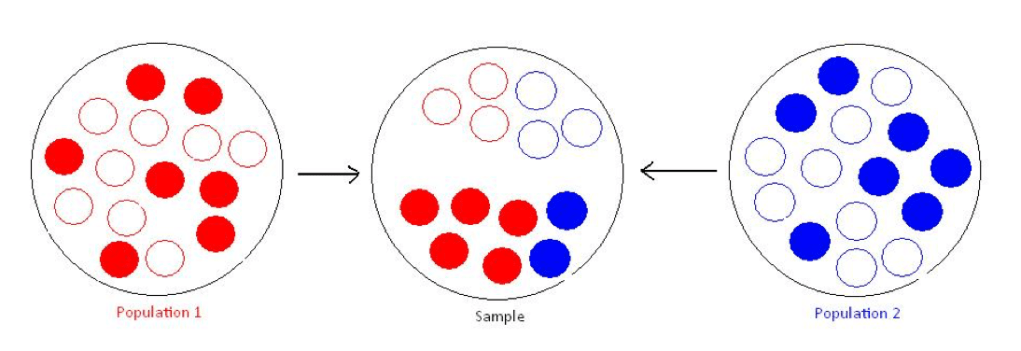
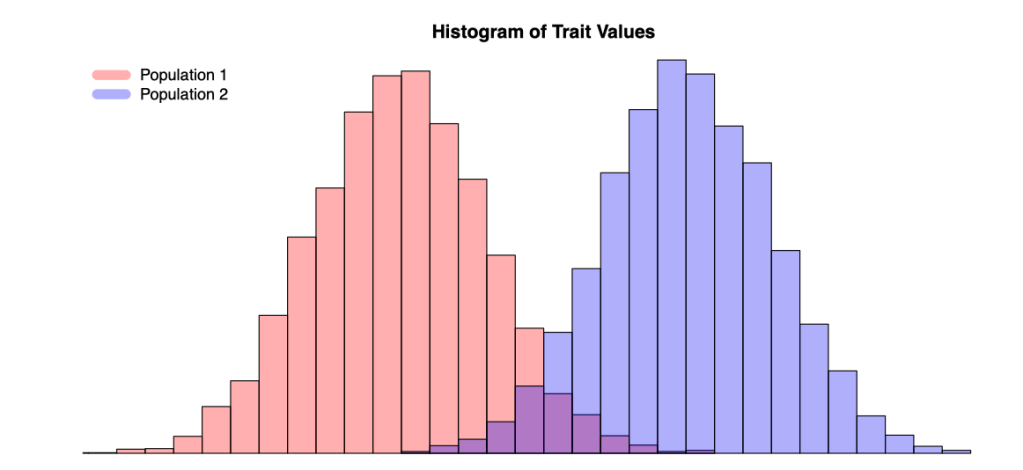
为了解决这个问题,我们通常会采用genomic control的方法,或是通过PCA来矫正。详见:
- Genomic control (基因组控制与基因组膨胀系数λ Genomic control λGC)
- PCA (群体分层与主成分分析 Population structure & PCA)
Cryptic relatedness
由于将主成分作为协变量纳入模型以矫正群体分层的方法,适用于样本中不存在亲缘关系的情况下使用,而样本中存在亲缘关系时,就不一定有效,但通常我们的研究中都会存在有亲缘关系的样本。
当样本中存在隐性关联 / 错误认定的关联 Cryptic and / or misspecified relatedness时,也可能会造成上述的虚假关联。由于我们通常不能掌握所有研究对象的家谱,所以无法完全去相关个体,例如下面的情况,样本中看似不相关的个体间实际上存在隐性关联:
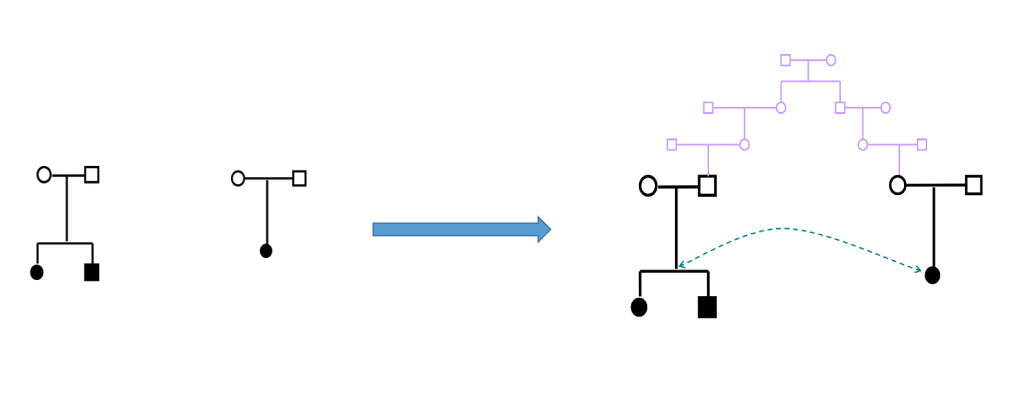
Linear Mixed Model
为了解决以上问题,相比早期的线性模型,我们就采用一种更为灵活的模型,线性混合模型来进行检验。
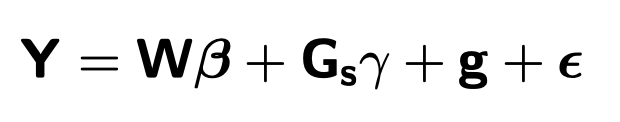
固定效应 fixed effects:
- W为 n x (w + 1)的矩阵,包含了截距,以及协变量
- β 则是 ( w + 1 ) × 1 的向量,表示协变量的效应量
- Gs为 n × 1 的向量,某个位点的基因型,每一项的值通常为 0,1,2(等位基因allele的拷贝数)
- γ则是标量,目标位点基因型的效应量
随机效应 random effects:
- g为长度为n的随机向量,表示多基因效应
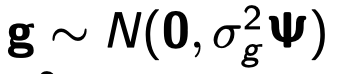
- δ2g为加性遗传方差
- Ψ是成对遗传相关的矩阵
- e是长度为n的随机向量,服从以下的分布,其中δ2e为非遗传效应造成的方差,我们认为这项在个体间是相互独立的
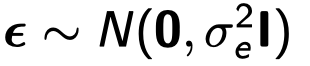
通常成对遗传相关的矩阵Ψ是未知的,在计算中我们使用empirical GRM(genetic relatedness matrix,通过纳入研究的SNP计算得出)
目前已有多种GWAS检验方法基于LMM模型,包括:
- EMMAX
- GEMMA
- GMMAT
- Bolt-LMM
- fastGWAS
- SAIGE
- 等等
参考:
Lecture 6: GWAS in Samples with Structure ,Summer Institute in Statistical Genetics 2015

《GWAS的线性混合模型LMM Linear Mixed Model》有2条评论