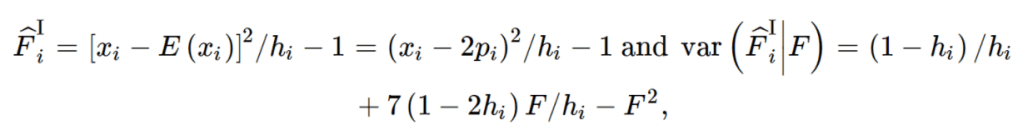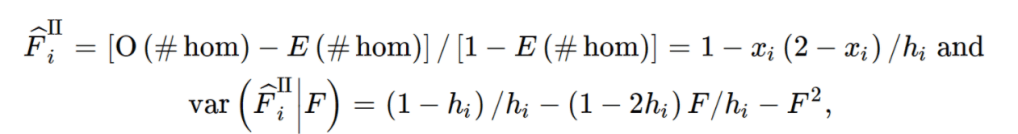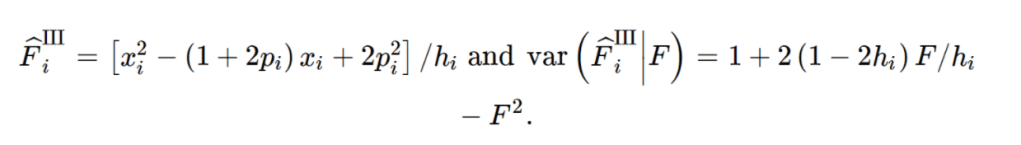本文内容:
eagle2简介
下载与安装
使用方法
无参考面板phasing
有参考面板phasing
输出
附录:eagle -h
参考
1.eagle2简介
Eagle是一款可在有参考面板或无参考面板的情况下,对样本的单倍体型进行估计的软件。 Eagle2目前是 Sanger 及Michigan 填充服务器的默认方法。该软件使用了一种快速的基于隐马尔科夫模型(HMM)的算法,大幅提升了速度与准确度。该软件的两个关键点为:基于 Burrows-Wheeler transform的一种新的数据结构,以及只探索HMM最相关路径的快速搜索算法。
2.下载与安装:
下载地址:http://data.broadinstitute.org/alkesgroup/Eagle/downloads/
文档地址:https://alkesgroup.broadinstitute.org/Eagle/Eagle_manual.html#x1-30002
平台要求:LINUX
内存要求:
无参考panel时,内存占用与样本数N以及SNP数呈线性关系。例如:UKBB 150K的样本,每1000个SNP需要1GB 内存。
有参考panel时,每个基因型需要约1.5个字节。
3 基本使用方法
下载安装后可以直接使用,选项可由以下格式指定 --optionName=optionValue.
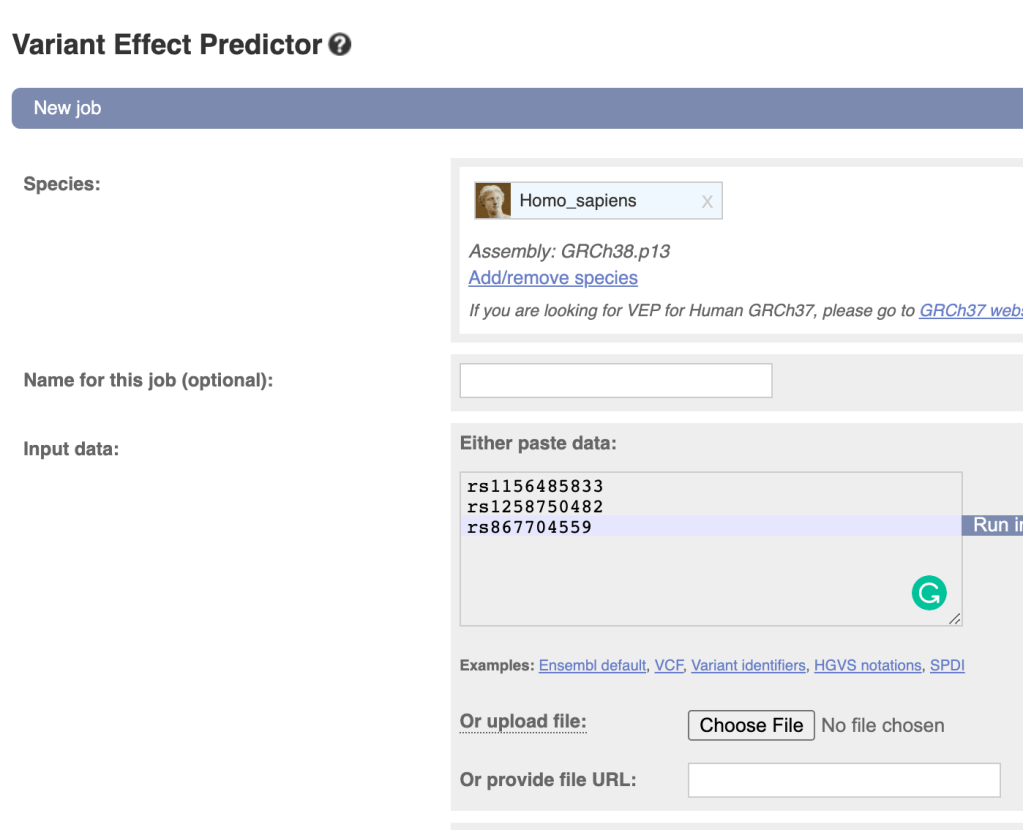
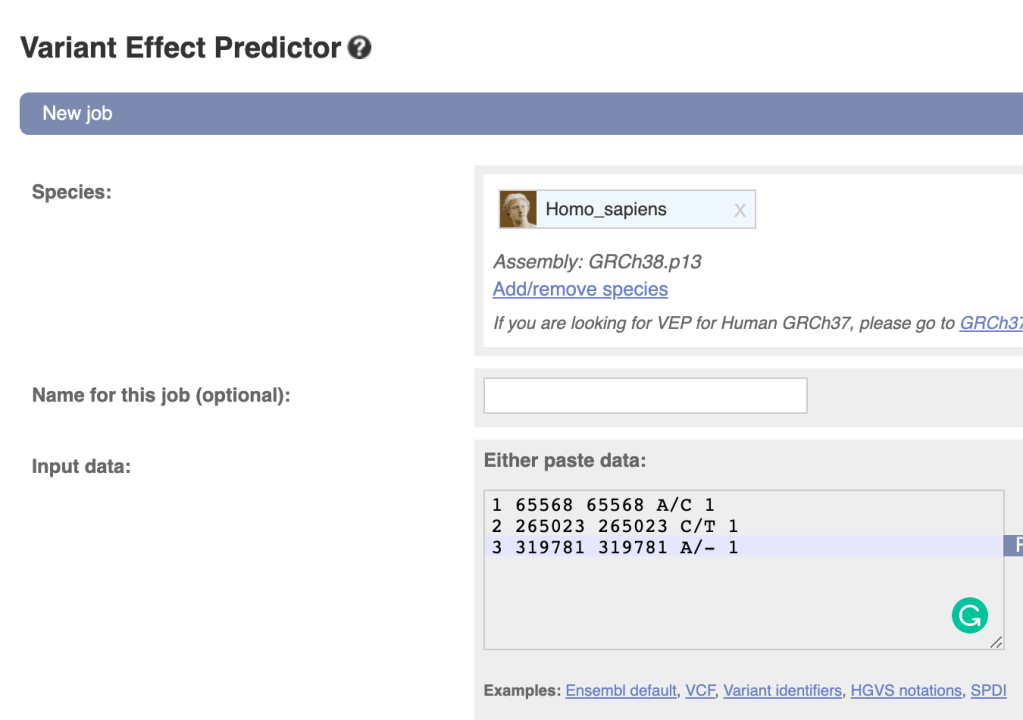
一个最简单的示例如下:
./eagle --bfile=plink --geneticMapFile=USE_BIM --outPrefix=phased
eagle支持多线程,可以使用--numThreads来指定eagle使用的CPU核心数。
4.1 无参考面板的Phasing
1.输入
使用-bfile=prefix 指定输入的PLINK文件,注意eagle一次只phase一条染色体,如果PLINK文件里包含多条染色体,则需要通过-chrom指定染色体。
注意: PLINK在表示chr X (chrom 23=X)的non-PAR部分时,将所有男性的未丢失的基因型都转换为纯合,在表示PAR1与PAR2时(chrom 25=XY),则使用一般的二倍体基因型。如果只是想对chr X 的non-PAR部分进行phasing,那么只需输入 chrom 23 即可。如果要对整个X染色体(包括PAR与non-PAR),那么需要首先将plink文件中PAR与non-PAR的基因型合并,(可以使用plink的-merge-x)。VCF文件则不需要额外处理。
2.参考的遗传图谱
如果你的PILNK文件没有相应的遗传坐标文件(单位为摩根),可以使用eagle提供的事先处理好的参考图谱(从HapMap下载并转换格式)。使用时,选项如下:
-geneticMapFile=tables/genetic_map_hg##_withX.txt.gz
3.缺失值处理
phasing过程中,缺失的基因型会被自动填补。eagle输出的是best-guess单倍体基因型。如果不需要自动填补,输入文件为VCF,BCF时,则可以使用 --noImpMissing 来禁用自动填补功能。
4.基因型QC
当使用PLINK文件时,eagle会根据丢失率自动对样本与SNP进行QC,默认的阈值为0.01(自动去掉丢失率高于1%的样本或SNP). eagle也可以通过指定–maxMissingPerSnp 与 –maxMissingPerIndiv 来手动对样本与SNP进行QC,但通常我们会使用QC过得PLINK文件,所以这一步可以使用–maxMissingPerSnp 1 与 –maxMissingPerIndiv 1(允许的最大丢失率为1,也就是没有施加任何QC)来略过这一步。在使用VCF文件时,eagle则不进行任何QC
5.样本与SNP的过滤
输入使用plink文件时,可以通过 –remove 与 –exclude 来对样本与SNP进行过滤
对于PLINK与VCF/BCF输入,可以使用 –bpStart and –bpEnd来限定phasing的区域(例如: –bpStart=50e6 以及–bpEnd=100e6)
6.模型参数指定
eagle2中主要调节运算速度与准确度平衡的参数选项为 –Kpbwt,该参数指定在各个样本的phasing中eagle2使用的调节单倍体型的数量,默认值为10000.
使用例:
./eagle \
--bfile=plink_hg19 \
--geneticMapFile=genetic_map_hg19_withX.txt.gz \
--chrom=1 \
--outPrefix=phased \
--maxMissingPerSnp=1 \
--maxMissingPerIndiv=1 \
--numThreads=8
4.2 有参考面板Phasing
注意如果你的样本量是参考面板样本量的两倍以上时,使用参考样本并不会大幅提升phasing的精度。使用参考面板时,输入只能是VCF或BCF格式,分别使用–vcfTarget and –vcfRef 里指定目标以及参考样本的经过tabix索引的vcf,bcf文件。
如果vcf,bcf文件中含有多条染色体的数据,那么需要用–chrom 来指定。
其余的选项与无参考时vcf输入的情况支持的选项相似。
参考面板可以使用1000 genome的数据,但须经过一定处理,详见:https://alkesgroup.broadinstitute.org/Eagle/ 中5.3 Reference panels from the 1000 Genomes Project
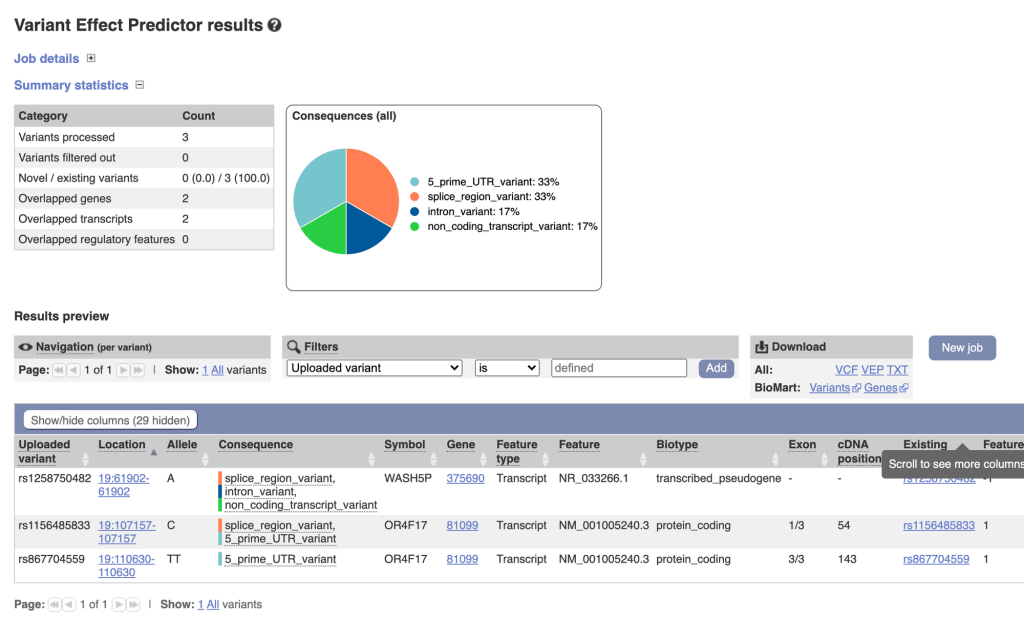
5 输出
当输入为PLINK文件时,eagle输出为gzip压缩后的Oxford HAPS/SAMPLE 格式文件 (详见SHAPEIT2 ),输出文件前缀可由–outPrefix 指定。
当输入为VCF,BCF文件时,输出也出VCF,BCF文件。输出文件前缀可由–outPrefix 指定。可用 –vcfOutFormat=z 指定输出文件格式。
6 附录
./eagle -h
+-----------------------------+
| |
| Eagle v2.4.1 |
| November 18, 2018 |
| Po-Ru Loh |
| |
+-----------------------------+
Copyright (C) 2015-2018 Harvard University.
Distributed under the GNU GPLv3+ open source license.
Command line options:
eagle -h
Options:
--geneticMapFile arg HapMap genetic map provided with download:
tables/genetic_map_hg##.txt.gz
--outPrefix arg prefix for output files
--numThreads arg (=1) number of computational threads
Input options for phasing without a reference:
--bfile arg prefix of PLINK .fam, .bim, .bed files
--bfilegz arg prefix of PLINK .fam.gz, .bim.gz, .bed.gz
files
--fam arg PLINK .fam file (note: file names ending in
.gz are auto-decompressed)
--bim arg PLINK .bim file
--bed arg PLINK .bed file
--vcf arg [compressed] VCF/BCF file containing input
genotypes
--remove arg file(s) listing individuals to ignore (no
header; FID IID must be first two columns)
--exclude arg file(s) listing SNPs to ignore (no header;
SNP ID must be first column)
--maxMissingPerSnp arg (=0.1) QC filter: max missing rate per SNP
--maxMissingPerIndiv arg (=0.1) QC filter: max missing rate per person
Input/output options for phasing using a reference panel:
--vcfRef arg tabix-indexed [compressed] VCF/BCF file for
reference haplotypes
--vcfTarget arg tabix-indexed [compressed] VCF/BCF file for
target genotypes
--vcfOutFormat arg (=.) b|u|z|v: compressed BCF (b), uncomp BCF (u),
compressed VCF (z), uncomp VCF (v)
--noImpMissing disable imputation of missing target
genotypes (. or ./.)
--allowRefAltSwap allow swapping of REF/ALT in target vs. ref
VCF
--outputUnphased output unphased sites (target-only,
multi-allelic, etc.)
--keepMissingPloidyX assume missing genotypes have correct ploidy
(.=haploid, ./.=diploid)
--vcfExclude arg tabix-indexed [compressed] VCF/BCF file
containing variants to exclude from phasing
Region selection options:
--chrom arg (=0) chromosome to analyze (if input has many)
--bpStart arg (=0) minimum base pair position to analyze
--bpEnd arg (=1e9) maximum base pair position to analyze
--bpFlanking arg (=0) (ref-mode only) flanking region to use
during phasing but discard in output
Algorithm options:
--Kpbwt arg (=10000) number of conditioning haplotypes
--pbwtIters arg (=0) number of PBWT phasing iterations (0=auto)
--expectIBDcM arg (=2.0) expected length of haplotype copying (cM)
--histFactor arg (=0) history length multiplier (0=auto)
--genoErrProb arg (=0.003) estimated genotype error probability
--pbwtOnly in non-ref mode, use only PBWT iters
(automatic for sequence data)
--v1 use Eagle1 phasing algorithm (instead of
default Eagle2 algorithm)
7 参考:
https://alkesgroup.broadinstitute.org/Eagle/
Loh P-R, Danecek P, Palamara PF, Fuchsberger C, Reshef YA, Finucane HK, Schoenherr S, Forer L, McCarthy S, Abecasis GR, Durbin R, and Price AL. Reference-based phasing using the Haplotype Reference Consortium panel. Nature Genetics (2016).